
昔日头条委托资深算法架构师曹欢欢博士,地下昔日头条的算法原理,以期推进整个行业问诊算法、建言算法;经过让算法通明,来消弭各界对算法的曲解,并逐渐推进整个行业让算法更好的造福社会。
以下为《昔日头条算法原理》全文。

昔日头条资深算法架构师曹欢欢:

本次分享将次要引见昔日头条引荐零碎概览以及内容剖析、用户标签、评价剖析,内容平安等原理。
一、零碎概览
引荐零碎,假如用方式化的方式去描绘实践上是拟合一个用户对内容称心度的函数,这个函数需求输出三个维度的变量。第一个维度是内容。头条如今曾经是一个综合内容平台,图文、视频、UGC小视频、问答、微头条,每种内容有很多本人的特征,需求思索怎样提取不同内容类型的特征做好引荐。第二个维度是用户特征。包括各种兴味标签,职业、年龄、性别等,还有很多模型刻划出的隐式用户兴味等。第三个维度是环境特征。这是挪动互联网时代引荐的特点,用户随时随地挪动,在任务场所、通勤、旅游等不同的场景,信息偏好有所偏移。结合三方面的维度,模型会给出一个预估,即揣测引荐内容在这一场景下对这一用户能否适宜。
这里还有一个成绩,如何引入无法直接权衡的目的?
引荐模型中,点击率、阅读工夫、点赞、评论、转发包括点赞都是可以量化的目的,可以用模型直接拟合做预估,看线上提升状况可以晓得做的好不好。但一个大体量的引荐零碎,效劳用户众多,不能完全由目标评价,引入数据目标以外的要素也很重要。
这里还有一个成绩,如何引入无法直接权衡的目的?
引荐模型中,点击率、阅读工夫、点赞、评论、转发包括点赞都是可以量化的目的,可以用模型直接拟合做预估,看线上提升状况可以晓得做的好不好。但一个大体量的引荐零碎,效劳用户众多,不能完全由目标评价,引入数据目标以外的要素也很重要。
比方广告和特型内容频控。像问答卡片就是比拟特殊的内容方式,其引荐的目的不完全是让用户阅读,还要思索吸援用户答复为社区奉献内容。这些内容和普通内容如何混排,怎样控制频控都需求思索。
此外,平台出于内容生态和社会责任的考量,像低俗内容的打压,标题党、低质内容的打压,重要新闻的置顶、加权、强插,低级别账号内容降权都是算法自身无法完成,需求进一步对内容停止干涉。
上面我将复杂引见在上述算法目的的根底上如何对其完成。
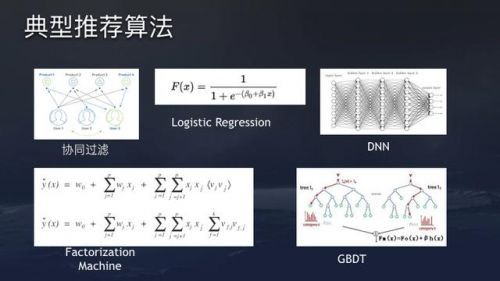
后面提到的公式y=F(Xi,X111.jpegu,Xc),是一个很经典的监视学习成绩。可完成的办法有很多,比方传统的协同过滤模型,监视学习算法LogisticRegression模型,基于深度学习的模型,FactorizationMachine和GBDT等。
一个优秀的工业级引荐零碎需求十分灵敏的算法实验平台,可以支持多种算法组合,包括模型构造调整。由于很难有一套通用的模型架构适用于一切的引荐场景。如今很盛行将LR和DNN结合,前几年Facebook也将LR和GBDT算法做结合。昔日头条旗下几款产品都在沿用同一套弱小的算法引荐零碎,但依据业务场景不同,模型架构会有所调整。

模型之后再看一下典型的引荐特征,次要有四类特征会对引荐起到比拟重要的作用。
第一类是相关性特征,就是评价内容的属性和与用户能否婚配。显性的婚配包括关键词婚配、分类婚配、来源婚配、主题婚配等。像FM模型中也有一些隐性婚配,从用户向量与内容向量的间隔可以得出。
第二类是环境特征,包括天文地位、工夫。这些既是bias特征,也能以此构建一些婚配特征。
第三类是热度特征。包括全局热度、分类热度,主题热度,以及关键词热度等。内容热度信息在大的引荐零碎特别在用户冷启动的时分十分无效。
第四类是协同特征,它可以在局部水平上协助处理所谓算法越推越窄的成绩。协同特征并非思索用户已有历史。而是经过用户行为剖析不同用户间类似性,比方点击类似、兴味分类类似、主题类似、兴味词类似,甚至向量类似,从而扩展模型的探究才能。
模型之后再看一下典型的引荐特征,次要有四类特征会对引荐起到比拟重要的作用。
第一类是相关性特征,就是评价内容的属性和与用户能否婚配。显性的婚配包括关键词婚配、分类婚配、来源婚配、主题婚配等。像FM模型中也有一些隐性婚配,从用户向量与内容向量的间隔可以得出。
第二类是环境特征,包括天文地位、工夫。这些既是bias特征,也能以此构建一些婚配特征。
第三类是热度特征。包括全局热度、分类热度,主题热度,以及关键词热度等。内容热度信息在大的引荐零碎特别在用户冷启动的时分十分无效。
第四类是协同特征,它可以在局部水平上协助处理所谓算法越推越窄的成绩。协同特征并非思索用户已有历史。而是经过用户行为剖析不同用户间类似性,比方点击类似、兴味分类类似、主题类似、兴味词类似,甚至向量类似,从而扩展模型的探究才能。

但由于头条目前的内容量十分大,加上小视频内容有千万级别,引荐零碎不能够一切内容全部由模型预估。所以需求设计一些召回战略,每次引荐时从海量内容中挑选出千级别的内容库。召回战略最重要的要求是功能要极致,普通超时不能超越50毫秒。
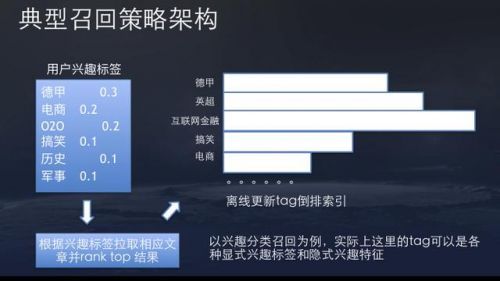
召回战略品种有很多,我们次要用的是倒排的思绪。离线维护一个倒排,这个倒排的key可以是分类,topic,实体,来源等,排序思索热度、新颖度、举措等。线上召回可以迅速从倒排中依据用户兴味标签对内容做截断,高效的从很大的内容库中挑选比拟靠谱的一小局部内容。

二、内容剖析
内容剖析包括文本剖析,图片剖析和视频剖析。头条一开端次要做资讯,明天我们次要讲一下文本剖析。文本剖析在引荐零碎中一个很重要的作用是用户兴味建模。没有内容及文本标签,无法失掉用户兴味标签。举个例子,只要晓得文章标签是互联网,用户看了互联网标签的文章,才干晓得用户有互联网标签,其他关键词也一样。

另一方面,文本内容的标签可以直接协助引荐特征,比方魅族的内容可以引荐给关注魅族的用户,这是用户标签的婚配。假如某段工夫引荐主频道效果不理想,呈现引荐窄化,用户会发现到详细的频道引荐(如科技、体育、文娱、军事等)中阅读后,再回主feed,引荐效果会更好。由于整个模型是打通的,子频道探究空间较小,更容易满足用户需求。只经过单一信道反应进步引荐精确率难度会比拟大,子频道做的好很重要。而这也需求好的内容剖析。

上图是昔日头条的一个实践文本case。可以看到,这篇文章有分类、关键词、topic、实体词等文本特征。当然不是没有文本特征,引荐零碎就不能任务,引荐零碎最晚期使用在Amazon,甚至沃尔玛时代就有,包括Netfilx做视频引荐也没有文本特征直接协同过滤引荐。但对资讯类产品而言,大局部是消费当天内容,没有文本特征新内容冷启动十分困难,协同类特征无法处理文章冷启动成绩。
昔日头条引荐零碎次要抽取的文本特征包括以下几类。首先是语义标签类特征,显式为文章打上语义标签。这局部标签是由人定义的特征,每个标签有明白的意义,标签体系是预定义的。此外还有隐式语义特征,次要是topic特征和关键词特征,其中topic特征是关于词概率散布的描绘,无明白意义;而关键词特征会基于一些一致特征描绘,无明白集合。

另外文本类似度特征也十分重要。在头条,已经用户反应最大的成绩之一就是为什么总引荐反复的内容。这个成绩的难点在于,每团体对反复的定义不一样。举个例子,有人觉得这篇讲皇马和巴萨的文章,昨天曾经看过相似内容,明天还说这两个队那就是反复。但关于一个重度球迷而言,尤其是巴萨的球迷,恨不得一切报道都看一遍。处理这一成绩需求依据判别类似文章的主题、行文、主体等外容,依据这些特征做线下策略。
异样,还有时空特征,剖析内容的发作地点以及时效性。比方武汉限行的事情推给北京用户能够就没有意义。最初还要思索质量相关特征,判别内容能否低俗,色情,能否是软文,鸡汤?

上图是头条语义标签的特征和运用场景。他们之间层级不同,要求不同。

分类的目的是掩盖片面,希望每篇内容每段视频都有分类;而实体体系要求精准,相反名字或内容要能明白区分终究指代哪一团体或物,但不必掩盖很全。概念体系则担任处理比拟准确又属于笼统概念的语义。这是我们最后的分类,理论中发现分类和概念在技术上能互用,后来一致用了一套技术架构。

分类的目的是掩盖片面,希望每篇内容每段视频都有分类;而实体体系要求精准,相反名字或内容要能明白区分终究指代哪一团体或物,但不必掩盖很全。概念体系则担任处理比拟准确又属于笼统概念的语义。这是我们最后的分类,理论中发现分类和概念在技术上能互用,后来一致用了一套技术架构。

分类的目的是掩盖片面,希望每篇内容每段视频都有分类;而实体体系要求精准,相反名字或内容要能明白区分终究指代哪一团体或物,但不必掩盖很全。概念体系则担任处理比拟准确又属于笼统概念的语义。这是我们最后的分类,理论中发现分类和概念在技术上能互用,后来一致用了一套技术架构。

目前,隐式语义特征曾经可以很好的协助引荐,而语义标签需求继续标注,新名词新概念不时呈现,标注也要不时迭代。其做好的难度和资源投入要远大于隐式语义特征,那为什么还需求语义标签?有一些产品上的需求,比方频道需求有明白定义的分类内容和容易了解的文本标签体系。语义标签的效果是反省一个公司NLP技术程度的试金石。

昔日头条引荐零碎的线上分类采用典型的层次化文本分类算法。最下面Root,上面第一层的分类是像科技、体育、财经、文娱,体育这样的大类,再上面细分足球、篮球、乒乓球、网球、田径、游泳...,足球再细分国际足球、中国足球,中国足球又细分中甲、中超、国度队...,相比独自的分类器,应用层次化文本分类算法能更好地处理数据倾斜的成绩。有一些例外是,假如要进步召回,可以看到我们衔接了一些飞线。这套架构通用,但依据不同的成绩难度,每个元分类器可以异构,像有些分类SVM效果很好,有些要结合CNN,有些要结合RNN再处置一下。
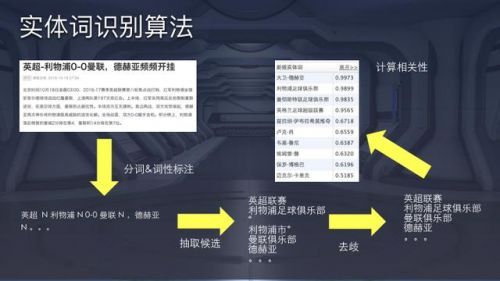
上图是一个实体词辨认算法的case。基于分词后果和词性标注选取候选,时期能够需求依据知识库做一些拼接,有些实体是几个词的组合,要确定哪几个词结合在一同能映射实体的描绘。假如后果映射多个实体还要经过词向量、topic散布甚至词频自身等去歧,最初计算一个相关性模型。
三、用户标签
内容剖析和用户标签是引荐零碎的两大基石。内容剖析触及到机器学习的内容多一些,相比而言,用户标签工程应战更大。

昔日头条常用的用户标签包括用户感兴味的类别和主题、关键词、来源、基于兴味的用户聚类以及各种垂直兴味特征(车型,体育球队,股票等)。还有性别、年龄、地点等信息。性别信息经过用户第三方社交账号登录失掉。年龄信息通常由模型预测,经过机型、阅读工夫散布等预估。常驻地点来自用户受权拜访地位信息,在地位信息的根底上经过传统聚类的办法拿到常驻点。常驻点结合其他信息,可以揣测用户的任务地点、出差地点、旅游地点。这些用户标签十分有助于引荐。

当然最复杂的用户标签是阅读过的内容标签。但这里触及到一些数据处置战略。次要包括:一、过滤噪声。经过停留工夫短的点击,过滤标题党。二、热点惩罚。对用户在一些抢手文章(如前段工夫PGOne的新闻)上的举措做降权处置。实际上,传达范围较大的内容,相信度会下降。三、工夫衰减。用户兴味会发作偏移,因而战略更倾向新的用户行为。因而,随着用户举措的添加,老的特征权重会随工夫衰减,新举措奉献的特征权重会更大。四、惩罚展示。假如一篇引荐给用户的文章没有被点击,相关特征(类别,关键词,来源)权重会被惩罚。当然同时,也要思索全局背景,是不是相关内容推送比拟多,以及相关的封闭和dislike信号等。
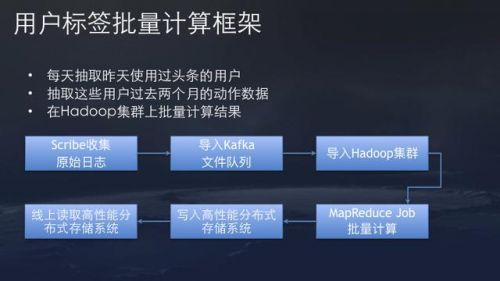
用户标签发掘总体比拟复杂,次要还是刚刚提到的工程应战。头条用户标签第一版是批量计算框架,流程比拟复杂,每天抽取昨天的日活用户过来两个月的举措数据,在Hadoop集群上批量计算后果。

但成绩在于,随着用户高速增长,兴味模型品种和其他批量处置义务都在添加,触及到的计算量太大。2014年,批量处置义务几百万用户标签更新的Hadoop义务,当天完成曾经开端勉强。集群计算资源紧张很容易影响其它任务,集中写入散布式存储零碎的压力也开端增大,并且用户兴味标签更新延迟越来越高。
面对这些应战。2014年底昔日头条上线了用户标签Storm集群流式计算零碎。改成流式之后,只需有用户举措更新就更新标签,CPU代价比拟小,可以节省80%的CPU工夫,大大降低了计算资源开支。同时,只需几十台机器就可以支撑每天数千万用户的兴味模型更新,并且特征更新速度十分快,根本可以做到准实时。这套零碎从上线不断运用至今。
当然,我们也发现并非一切用户标签都需求流式零碎。像用户的性别、年龄、常驻地点这些信息,不需求实时反复计算,就依然保存daily更新。
四、评价剖析
下面引见了引荐零碎的全体架构,那么如何评价引荐效果好不好?
有一句我以为十分有智慧的话,“一个事情没法评价就没法优化”。对引荐零碎也是一样。
现实上,很多要素都会影响引荐效果。比方侯全集合变化,召回模块的改良或添加,引荐特征的添加,模型架构的改良在,算法参数的优化等等,不逐个举例。评价的意义就在于,很多优化最终能够是负向效果,并不是优化上线后效果就会改良。
片面的评价引荐零碎,需求齐备的评价体系、弱小的实验平台以及易用的经历剖析工具。所谓齐备的体系就是并非单一目标权衡,不能只看点击率或许停留时长等,需求综合评价。过来几年我们不断在尝试,能不能综合尽能够多的目标分解独一的评价目标,但仍在探究中。目前,我们上线还是要由各业务比拟资深的同窗组成评审委员会深化讨论后决议。
很多公司算法做的不好,并非是工程师才能不够,而是需求一个弱小的实验平台,还有便捷的实验剖析工具,可以智能剖析数据目标的相信度。
一个良好的评价体系树立需求遵照几个准绳,首先是统筹短期目标与临时目标。我在之前公司担任电商方向的时分察看到,很多战略调整短期内用户觉得新颖,但是临时看其实没有任何助益。
其次,要统筹用户目标和生态目标。昔日头条作为内容分创作平台,既要为内容创作者提供价值,让他更有尊严的创作,也有义务满足用户,这两者要均衡。还有广告主利益也要思索,这是多方博弈战争衡的进程。
另外,要留意协同效应的影响。实验中严厉的流量隔离很难做到,要留意内部效应。
弱小的实验平台十分直接的优点是,当同时在线的实验比拟多时,可以由平台自动分配流量,无需人工沟通,并且实验完毕流量立刻回收,进步管理效率。这能协助公司降低剖析本钱,放慢算法迭代效应,使整个零碎的算法优化任务可以疾速往前推进。
这是头条A/BTest实验零碎的根本原理。首先我们会做在离线形态下做好用户分桶,然后线上分配实验流量,将桶里用户打上标签,分给实验组。举个例子,开一个10%流量的实验,两个实验组各5%,一个5%是基线,战略和线上大盘一样,另外一个是新的战略。
实验进程中用户举措会被搜集,根本上是准实时,每小时都可以看到。但由于小时数据有动摇,通常是以天为工夫节点来看。举措搜集后会有日志处置、散布式统计、写入数据库,十分便捷。
在这个零碎下工程师只需求设置流量需求、实验工夫、定义特殊过滤条件,自定义实验组ID。零碎可以自动生成:实验数据比照、实验数据相信度、实验结论总结以及实验优化建议。
当然,只要实验平台是远远不够的。线上实验平台只能经过数据目标变化揣测用户体验的变化,但数据目标和用户体验存在差别,很多目标不能完全量化。很多改良依然要经过人工剖析,严重改良需求人工评价二次确认。
五、内容平安
最初要引见昔日头条在内容平安上的一些举措。头条如今曾经是国际最大的内容创作与分发凭条,必需越来越注重社会责任和行业指导者的责任。假如1%的引荐内容呈现成绩,就会发生较大的影响。
因而头条从创建伊始就把内容平安放在公司最高优先级队列。成立之初,曾经专门设有审核团队担任内容平安。事先研发一切客户端、后端、算法的同窗一共才不到40人,头条十分注重内容审核。
如今,昔日头条的内容次要来源于两局部,一是具有成熟内容消费才能的PGC平台
一是UGC用户内容,如问答、用户评论、微头条。这两局部内容需求经过一致的审核机制。假如是数量绝对少的PGC内容,会直接停止风险审核,没有成绩会大范围引荐。UGC内容需求经过一个风险模型的过滤,有成绩的会进入二次风险审核。审核经过后,内容会被真正停止引荐。这时假如收到一定量以上的评论或许告发负向反应,还会再回到复审环节,有成绩直接下架。整个机制绝对而言比拟健全,作为行业抢先者,在内容平安上,昔日头条不断用最高的规范要求本人。
分享内容辨认技术次要鉴黄模型,咒骂模型以及低俗模型。昔日头条的低俗模型经过深度学习算法训练,样本库十分大,图片、文本同时剖析。这局部模型更注重召回率,精确率甚至可以牺牲一些。咒骂模型的样本库异样超越百万,召回率高达95%+,精确率80%+。假如用户常常出言不讳或许不当的评论,我们有一些惩罚机制。
泛低质辨认触及的状况十分多,像假新闻、黑稿、题文不符、标题党、内容质量高等等,这局部内容由机器了解是十分难的,需求少量反应信息,包括其他样本信息比对。目前低质模型的精确率和召回率都不是特别高,还需求结合人工复审,将阈值进步。目前最终的召回已到达95%,这局部其实还有十分多的任务可以做。头条人工智能实验室李航教师目前也在和密歇根大学共建科研项目,设立谣言辨认平台。
-
成都理工大学是985还是211 成都理工学
2017年9月,教育部公布了世界一流大学和一流学科建设高校及建设学科名单。在这个名单里,冲出了一匹黑马——成都理工大学。为什么这么说呢?因为成都理工大学既不是“985工程”,也不是“…
-
泰山科技学院 泰山科技学费多少钱
泰山科技学院是一所民办性质的本科大学,是由原来的山东科技大学泰山科技学院转设而来,目前开设有24个本科专业、20个专科专业,同比2021年之前,在2022年统招中新增了4个专科专业、3个本科专业,不过…
-
有希望的男人 《瑜伽教练3》韩剧
男人是很现实的生物,他们在选择情人时也是如此。大多数男人希望找到的情人都具有以下三种特质。第一种美貌动人美貌是吸引男人的重要因素之一。许多男人会对容貌出众的女性产生浓厚的兴趣。这并不是说男人只重视外…
-
怎么看淘宝一共花了多少钱 在哪查淘宝
快科技5月8日消息,近期,淘宝发布时光机活动,用户可查看自己近20年的消费情况。访问方式在淘宝搜索栏“淘宝时光机”即可。其中,用户可查到自己首次使用淘宝的日期,共花费的钱数、下单数,全国排名,近五年…





